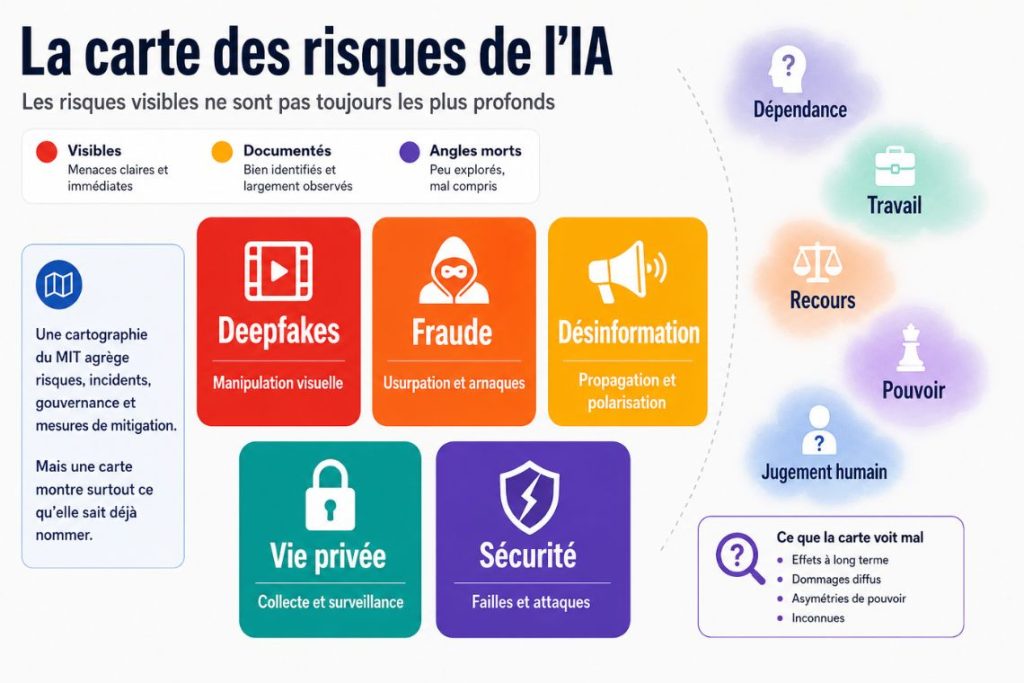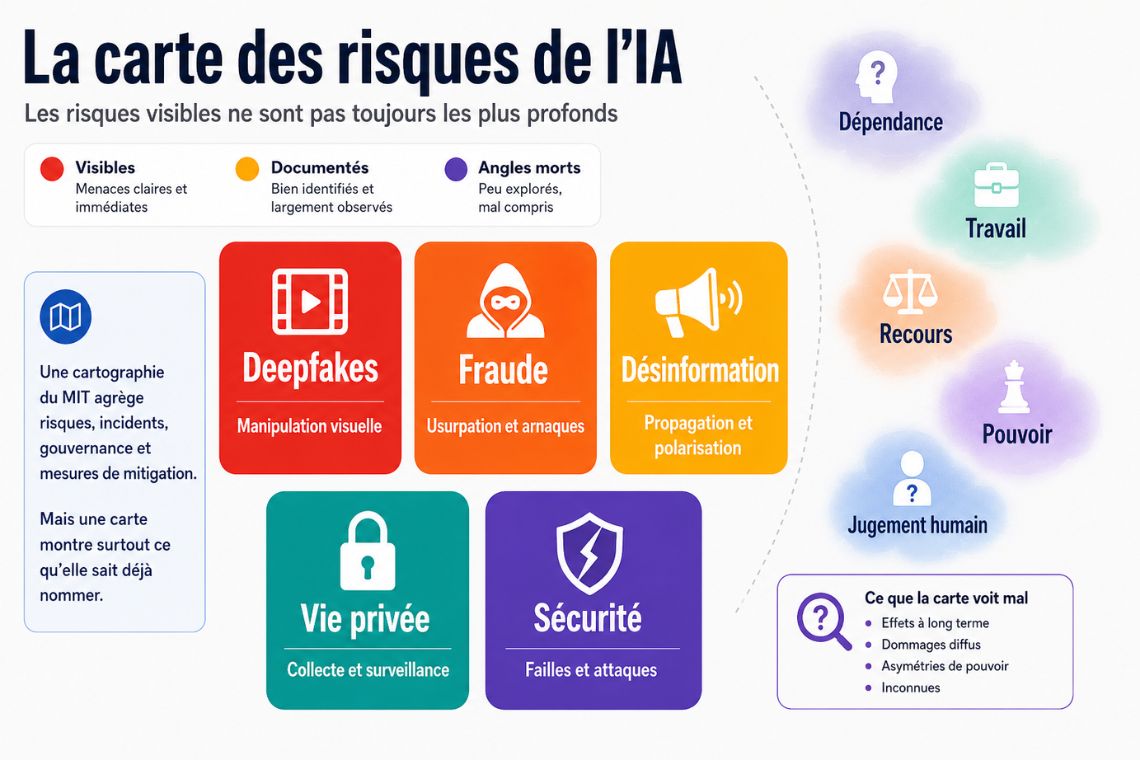
Les risques visibles ne sont pas toujours les plus profonds
Un deepfake politique laisse une trace. Une voix clonée utilisée dans une arnaque laisse une plainte, un article, parfois une enquête. Une image synthétique virale laisse des captures, des indignations, des démentis. Ces risques-là entrent facilement dans une base. Ils ont une scène, une date, des victimes identifiables, parfois un coupable. Ils se racontent bien.
Une dépendance progressive à quelques modèles propriétaires laisse moins de traces. Une décision algorithmique discriminatoire peut être subie sans être comprise, contestée sans être prouvée, vécue sans devenir un cas. Une dégradation des conditions de travail liée à l’automatisation n’apparaît pas toujours comme un « incident IA ». Un affaiblissement du jugement humain, une perte de recours, une délégation lente de décisions sensibles à des systèmes opaques n’ont pas forcément le panache d’un scandale.
Le MIT AI Risk Navigator s’inscrit exactement dans cette tension. L’outil entend cartographier les risques de l’intelligence artificielle, en reliant plusieurs bases de données autour d’une même taxonomie. Sa promesse est utile, presque nécessaire. Le débat sur l’IA est devenu illisible. Mais l’intérêt du Navigator ne tient pas seulement à ce qu’il montre. Il tient surtout à ce qu’il aide à interroger.
Car les risques que l’on sait compter ne sont pas toujours ceux qui comptent le plus.
Une carte pour un débat saturé
Depuis l’explosion de l’IA générative, chacun parle depuis son propre observatoire. Les chercheurs évoquent la robustesse des modèles, l’alignement, les capacités émergentes ou les défaillances systémiques. Les régulateurs parlent conformité, transparence, responsabilité et droits fondamentaux. Les entreprises cherchent des grilles d’audit, des procédures de sécurité, des processus de reporting. Les citoyens voient passer des arnaques automatisées, des deepfakes, des chatbots trop convaincants, des décisions opaques et des promesses d’efficacité qui ressemblent parfois à des suppressions de postes.
Dans ce désordre, le MIT propose une carte. Airi Navigator, aussi appelé MIT AI Risk Navigator, rassemble plusieurs bases de données produites ou intégrées autour du MIT AI Risk Initiative. L’ambition consiste à relier quatre registres souvent séparés. Les risques décrits par la recherche, les incidents déjà documentés, les documents de gouvernance et les mesures destinées à réduire ces risques. Le tout est organisé selon une taxonomie commune, c’est-à-dire une grille de classement qui sert de langage partagé.
L’exercice a une vertu évidente. Il oblige à sortir du grand mot « IA », trop large pour dire quoi que ce soit de précis. Entre un modèle qui hallucine une information médicale, une fraude au deepfake vocal, une discrimination dans un système de recrutement, une fuite de données, une dépendance économique à quelques fournisseurs ou une explosion de contenus synthétiques, le risque n’a ni la même forme, ni les mêmes victimes, ni les mêmes responsables. Mettre ces réalités dans une architecture commune aide à comparer ce qui, d’ordinaire, reste dispersé.
Mais cette mise en ordre porte une ambiguïté. Une carte donne toujours une impression de maîtrise. Elle transforme le flou en zones, les alertes en catégories, les cas isolés en séries. Elle produit de la lisibilité, donc de l’autorité. Or, dans le cas de l’IA, la carte ne représente pas directement le réel. Elle représente d’abord les traces disponibles du réel.
Des données, pas une photographie du monde
Le Navigator impressionne par son ampleur. Il agrège plus d’un millier de risques, plus d’un millier d’incidents, plus d’un millier de documents de gouvernance et plusieurs centaines de mesures de mitigation. Ces volumes donnent au débat une texture de preuve. Ils offrent aussi un confort intellectuel. Face à une technologie qui avance vite, une base de données donne le sentiment que l’on reprend la main.
Le piège commence ici. Ces chiffres ne mesurent pas mécaniquement la gravité des risques. Ils mesurent d’abord une présence dans des corpus. Un sujet très représenté peut être mieux étudié, mieux médiatisé, plus facile à détecter ou plus simple à traduire dans des textes de gouvernance. Un sujet moins présent peut être secondaire, mais il peut aussi être diffus, récent, mal signalé, politiquement inconfortable ou vécu par des publics qui laissent peu de traces dans les bases.
Les incidents d’IA ne recouvrent donc pas l’ensemble des incidents d’IA. Ils recouvrent ce qui a été repéré, documenté, collecté, vérifié, classé. Une arnaque générée par IA qui fait la une entre plus facilement dans une base qu’une dégradation progressive des conditions de travail liée à l’automatisation. Une personne écartée par un système de tri automatisé, un étudiant surveillé par un logiciel intrusif, un allocataire confronté à une décision opaque, un patient exposé à une recommandation automatisée discutable n’ont pas toujours les moyens de transformer leur expérience en incident reconnu. La donnée disponible ne dit pas seulement quelque chose du risque. Elle dit aussi quelque chose du pouvoir de le signaler.
Le même raisonnement vaut pour les textes de gouvernance. Leur présence ne signifie pas qu’un risque est maîtrisé. Elle indique qu’il est nommé par des institutions, intégré dans des cadres, discuté dans des normes ou des politiques publiques. Entre écrire un principe de transparence et garantir une transparence réelle, il reste tout le chemin de l’application, du contrôle, de la preuve et de la sanction. La gouvernance produit des documents avant de produire des effets.
La visibilité n’est pas la gravité
L’une des erreurs les plus courantes dans le débat sur l’IA consiste à confondre visibilité et importance. Les risques spectaculaires remontent vite. Un faux discours politique généré par IA, une voix clonée utilisée pour une escroquerie, une image synthétique virale ou un chatbot qui dérape offrent un récit clair. Le spectaculaire attire l’attention parce qu’il se raconte bien.
Les risques structurels avancent moins bruyamment. Ils n’ont pas toujours de date, de scène, de rupture nette. Ils prennent la forme d’une délégation progressive du jugement, d’une perte de compétence, d’une concentration du pouvoir technique, d’une dépendance à quelques modèles propriétaires, d’un affaiblissement des recours humains, d’une pollution informationnelle continue. Ces risques-là ne produisent pas toujours un scandale identifiable. Ils s’accumulent, se normalisent, puis finissent par organiser le système lui-même.
C’est ici que le MIT AI Risk Navigator devient intéressant, à condition de ne pas le lire comme un palmarès des dangers. Sa valeur se trouve dans les écarts entre les couches. Un risque très présent dans la recherche, mais peu visible dans les incidents interroge notre capacité à l’observer. Un risque fréquent dans les incidents, mais peu couvert par les textes de gouvernance signale un possible retard institutionnel. Un risque abondamment traité par des cadres normatifs, mais difficile à relier à des effets concrets pose une question d’efficacité. La carte ne dit pas seulement où sont les risques. Elle montre où les discours ne coïncident pas.
Cette dissonance est précieuse. Elle empêche de réduire les risques de l’IA à ce qui fait déjà scandale. Elle rappelle aussi que l’absence de données n’est pas une preuve d’absence de danger. Dans les technologies numériques, les dommages les plus profonds sont parfois ceux qui se normalisent avant d’être nommés.
Classer, c’est gouverner
Le Navigator repose sur une taxonomie en grandes familles. Discrimination et toxicité. Vie privée et sécurité. Désinformation. Acteurs malveillants et usages abusifs. Interaction humain-machine. Risques socio-économiques et environnementaux. Sécurité, défaillances et limites des systèmes d’IA. À première vue, cette grille a tout d’un outil technique. Elle donne des cases, des filtres, des repères.
En réalité, une taxonomie n’est jamais neutre. Elle détermine ce qui entre dans le champ, ce qui reste à la marge, ce qui mérite d’être regroupé ou séparé. Dire « désinformation » ne cadre pas le problème comme « manipulation politique ». Dire « interaction humain-machine » ne produit pas le même effet que parler de dépendance émotionnelle, d’exploitation de la vulnérabilité ou de délégation excessive de décisions. Dire « sécurité du système » ne met pas l’accent au même endroit que « responsabilité du fournisseur ».
Le classement agit donc comme une grammaire du risque. Il influence la manière dont les régulateurs rédigent, dont les entreprises auditent, dont les chercheurs cherchent, dont les médias racontent. Un risque doté d’une catégorie circule mieux. Il devient plus facile à citer, à mesurer, à surveiller, à financer. Un risque mal logé dans la grille reste plus fragile. Il existe peut-être dans les usages, mais il peine à exister dans les tableaux.
Le mérite du MIT est de rendre cette grammaire visible. Le danger serait de l’oublier. Une bonne taxonomie aide à penser. Une taxonomie trop vite naturalisée finit par enfermer la pensée.
Après la ruée vers l’IA, la ruée vers son encadrement
L’AI Risk Navigator raconte aussi une évolution plus large. L’IA entre dans son âge des registres, des matrices, des bases d’incidents, des référentiels, des cadres de conformité et des bibliothèques de mitigation. Après les démonstrations spectaculaires et les promesses commerciales, la question n’est plus seulement de savoir ce que ces systèmes savent faire. Elle devient plus sèche. Qui les contrôle, qui les audite, qui documente leurs dommages, qui vérifie les réponses ?
Cette phase était inévitable. Une technologie déployée dans l’éducation, la santé, la finance, les médias, la sécurité, le recrutement ou l’administration ne reste pas éternellement dans le registre de l’émerveillement technique. Elle appelle des preuves, des responsabilités, des procédures, des garde-fous. Le risque devient un objet de gestion. Il faut le nommer, l’attribuer, le réduire, le documenter.
Ce mouvement a une vertu. Il discipline un débat souvent paresseux, où « l’IA » sert de mot-valise pour tout désigner. Il oblige à distinguer les abus humains, les défaillances techniques, les dommages sociaux, les vulnérabilités de sécurité, les effets économiques, les lacunes réglementaires. Il fournit aussi des points d’appui aux journalistes, chercheurs, associations et régulateurs qui veulent sortir du commentaire général.
Mais la bureaucratisation a son revers. Elle transforme parfois les problèmes en cases à cocher. Elle donne l’impression qu’un risque relié à une mesure de mitigation entre déjà en voie de traitement, alors que tout dépend de l’application réelle, des moyens de contrôle, du pouvoir des autorités et de la capacité des victimes à faire valoir leurs droits. Dans le domaine de l’IA, comme ailleurs, la conformité peut devenir un langage de protection ou un théâtre de protection.
Le travail commence dans les écarts
Le MIT ne livre pas une vérité définitive sur les risques de l’intelligence artificielle. Il livre un instrument de lecture. Sa force vient de sa capacité à faire apparaître les décalages entre ce que la recherche anticipe, ce que les incidents révèlent, ce que la gouvernance encadre et ce que les mesures de mitigation prétendent traiter.
Pour un journaliste, l’outil ne remplace pas l’enquête. Il donne une méthode pour la lancer. Chercher les catégories saturées de discours, mais pauvres en preuves. Identifier les risques très visibles, mais déjà bien encadrés. Repérer les dommages qui touchent des publics moins audibles. Observer les sujets traités par les institutions avant même qu’ils soient massivement documentés. Interroger les domaines où les réponses normatives semblent plus rapides que la compréhension empirique.
À condition de ne pas être lu comme un classement définitif, le MIT AI Risk Navigator devient alors un outil précieux. Il ne dit pas quels risques doivent dominer le débat, il montre quels risques disposent déjà d’un langage, d’une base, d’un incident, d’un texte ou d’une mesure de mitigation. Le travail commence dans les écarts. Quels risques savent déjà se faire entendre ? Quels risques restent trop diffus pour entrer dans les tableaux ? Quels dommages touchent des populations peu documentées ? Quels sujets attirent beaucoup de textes, mais peu d’effets mesurables ? Quels domaines attendent encore leurs scandales pour être pris au sérieux ? La carte du MIT ne clôt pas le débat sur les risques de l’IA. Elle le déplace vers une question plus dérangeante, celle de notre capacité collective à voir ce que nous prétendons gouverner.
Thomas LÉGER
Hexadef Capital – Hexablock
Airi Navigator, de quoi parle-t-on ?
Airi Navigator, ou MIT AI Risk Navigator, est une interface de navigation consacrée aux risques liés à l’intelligence artificielle. Le site agrège plusieurs bases de données du MIT AI Risk Initiative autour d’une même taxonomie. Son objectif tient en une formule simple. Relier dans un même outil les risques théoriques décrits par la recherche, les incidents réels documentés, les textes de gouvernance et les mesures destinées à réduire ces risques.
L’interface s’appuie sur plusieurs ensembles de données. L’AI Risk Repository recense des risques issus de la littérature spécialisée. L’AI Incident Tracker rassemble des incidents liés à l’IA. La Governance Mapping Database organise des documents de gouvernance. La Mitigation Database regroupe des actions de réduction des risques.
Le tout repose sur une grille en sept grands domaines. Discrimination et toxicité, vie privée et sécurité, désinformation, acteurs malveillants et usages abusifs, interaction humain-machine, risques socio-économiques et environnementaux, sécurité et limites des systèmes d’IA. L’intérêt de l’outil vient du croisement entre ces bases. Un même domaine de risque peut être très présent dans la recherche, peu visible dans les incidents, très couvert par la gouvernance ou mal relié à des mesures concrètes.